Member-only story
Enhancing Text-to-SQL Agents with Step-by-Step Reasoning
One cool outcome of the DeepSeek R1 release is that LLM is now starting to show the Thinking <think> tokens in the response, similar to ChatGPT-o1 and o3-mimi. Encouraging an LLM to think more deeply has a lot of benefits:
- No more black-box answers! You can see the reasoning behind your LLM’s responses in real-time.
- Users get insight into how the model reaches its conclusions.
- Spot and fix prompt mistakes with clarity.
- Transparency makes AI decisions feel more reliable.
- When humans and AI share reasoning, working together becomes effortless.
So here we are, I’ve built a RAG that brings a similar reasoning process (CoT responses) to the LangGraph SQL agent with tool calling. It is a ReAct agent (Reason + Act) that combines LangGraph’s SQL toolkit with a graph-based execution. Here’s how it works:
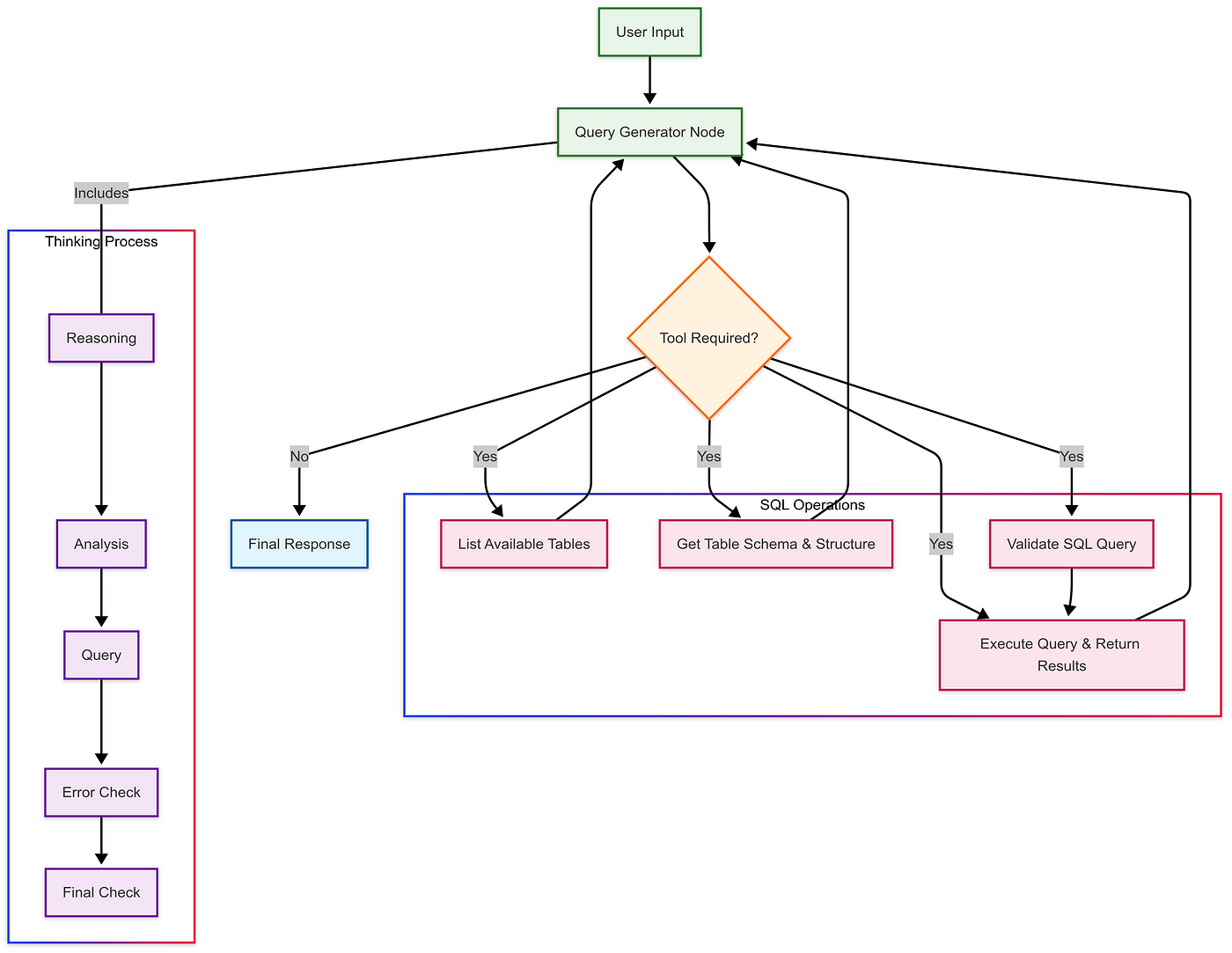
Now, let’s understand the thinking process.
The agent starts with a system prompt that structures its thinking:
I’ve mapped out the exact steps our SQL agent takes, from the moment it receives a question until it returns the final query:
Four-Phase Thinking Process
Reasoning Phase (<reasoning> tag)
- Explains information needs
- Describes expected outcomes
- Identifies challenges
- Justifies approach
Analysis Phase (<analysis> tag)
- Tables and joins needed
- Required columns
- Filters and conditions
- Ordering/grouping logic
Query Phase (<query> tag)
- Constructs SQL following rules:
- SELECT statements only
- Proper syntax
- Default LIMIT 10
- Verified schema
Verification Phase (<error_check> and <final_check> tags)
- Validates reasoning
